haruspex+semgrep
https://security.humanativaspa.it/automating-binary-vulnerability-discovery-with-ghidra-and-semgrep/
1.提取 Ghidra 反编译器生成的所有伪代码,使其格式适合导入 IDE(例如VS Code)或由静态分析工具(例如Semgrep)解析。
2.使用 Semgrep 和我的自定义 C/C++ 规则来(重新)发现一些漏洞
https://github.com/0xdea/semgrep-rules

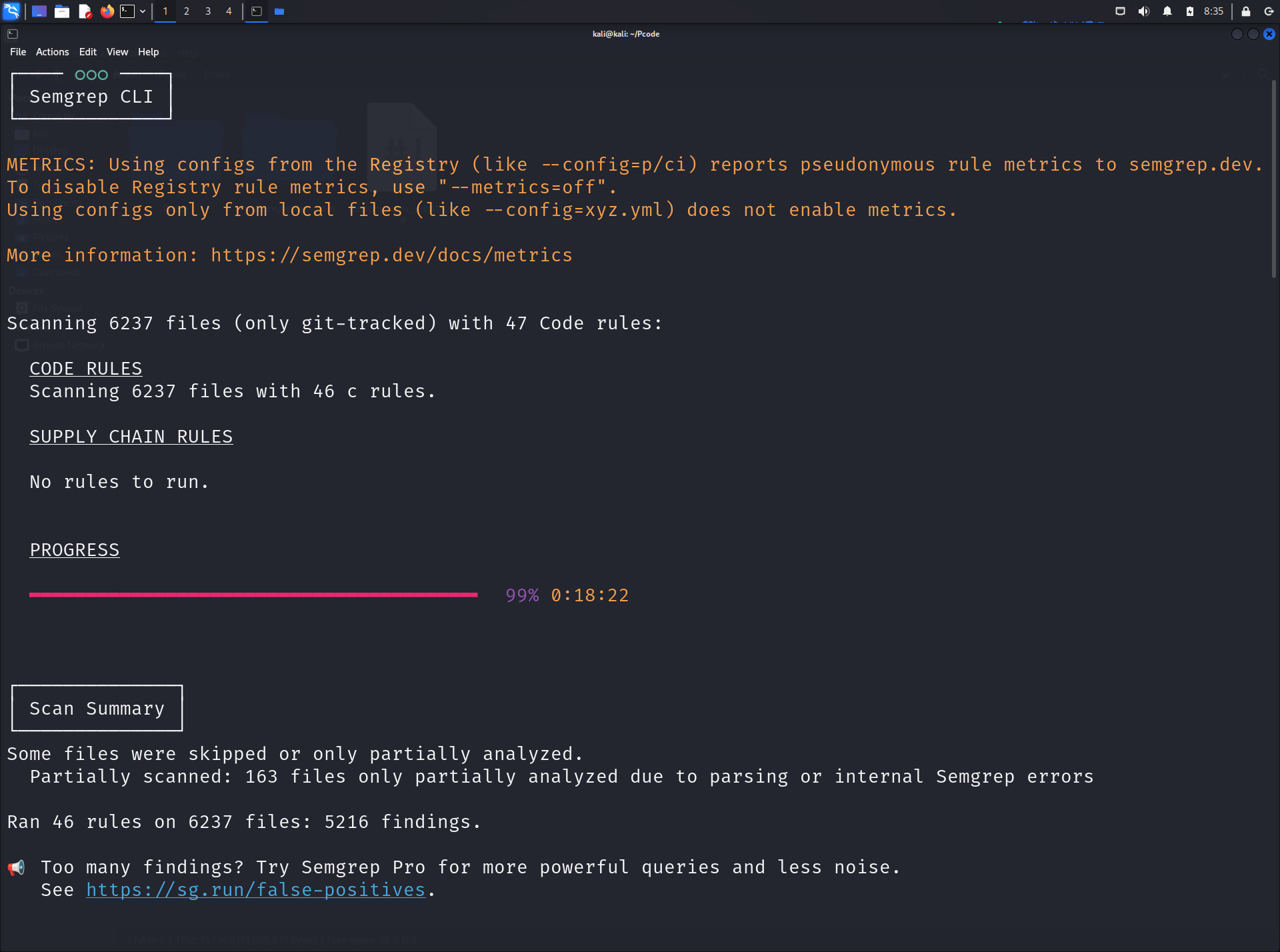
semgrep –config /home/kali/Pcode/semgrep-rules-main/c/ /home/kali/Pcode/Pcode/ –sarif -o custom_rules_result.sarif
第一次扫描结果:
第二次扫描结果:
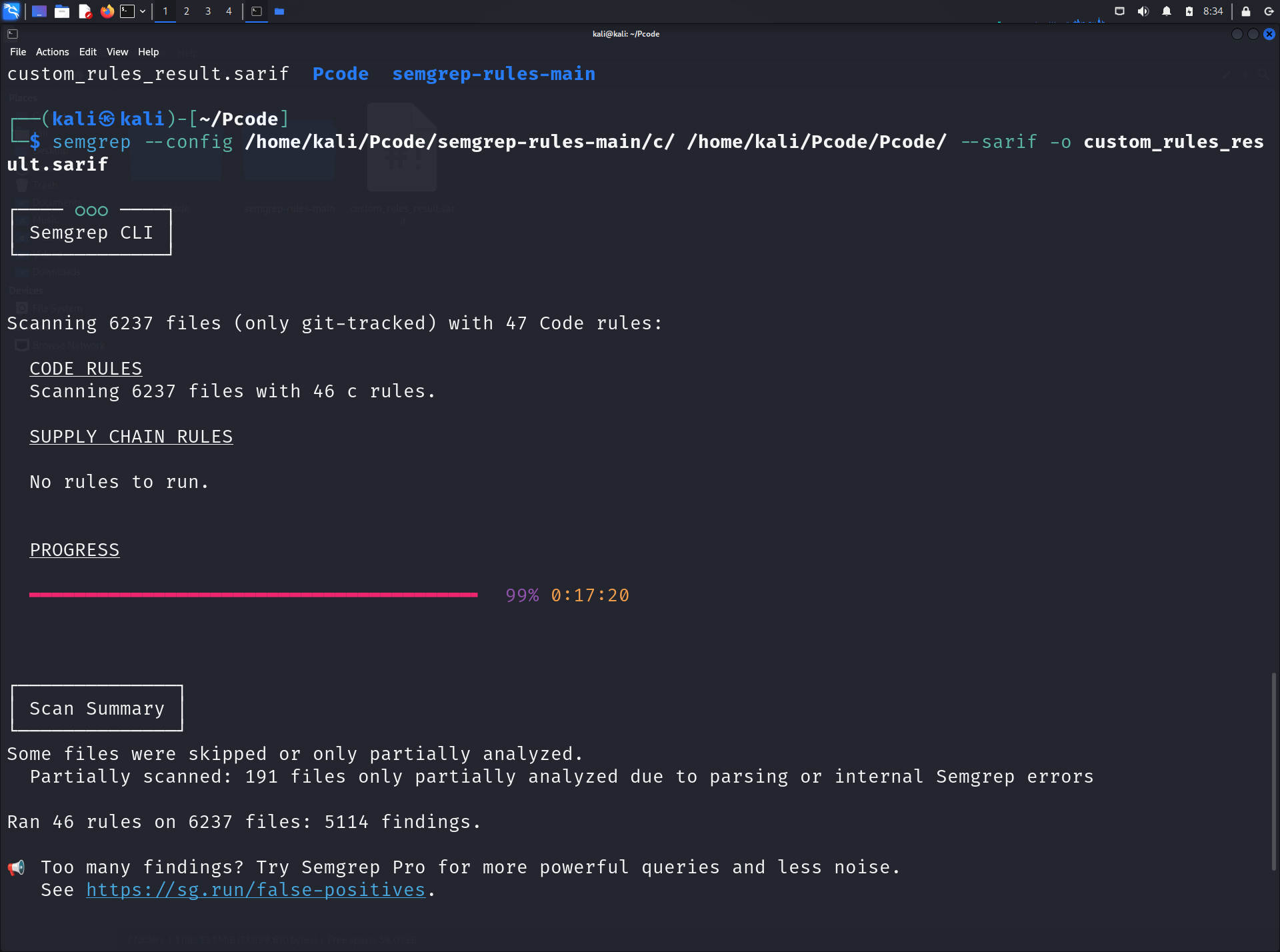
超时问题。
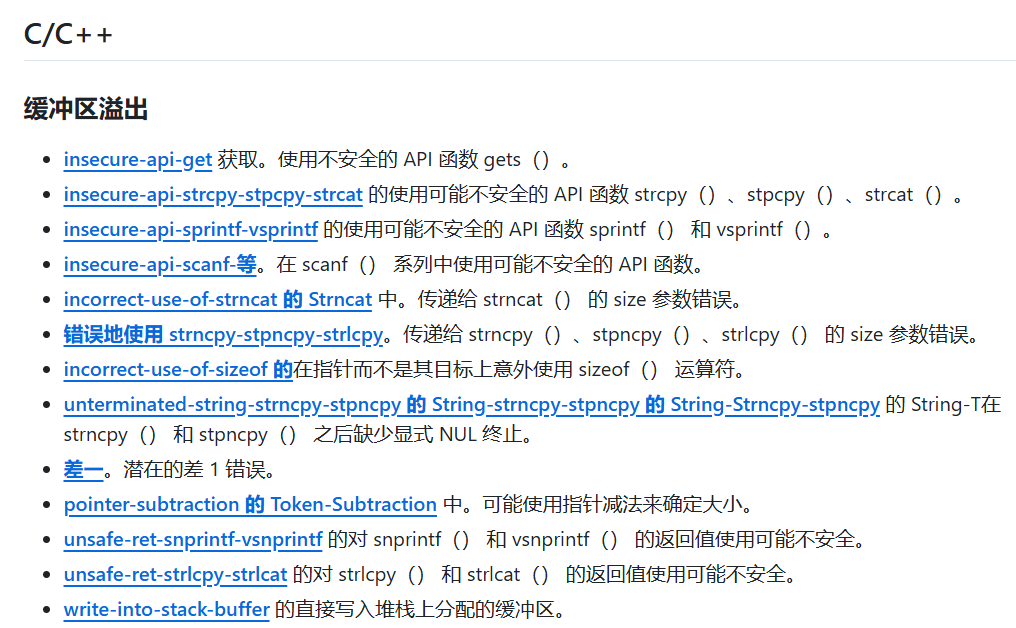
分析具体规则,缓冲区溢出,
分析具体规则:



用单个规则跑全部的pcode:
自信程度:high
1.command-injection 命令注入 自信程度:high
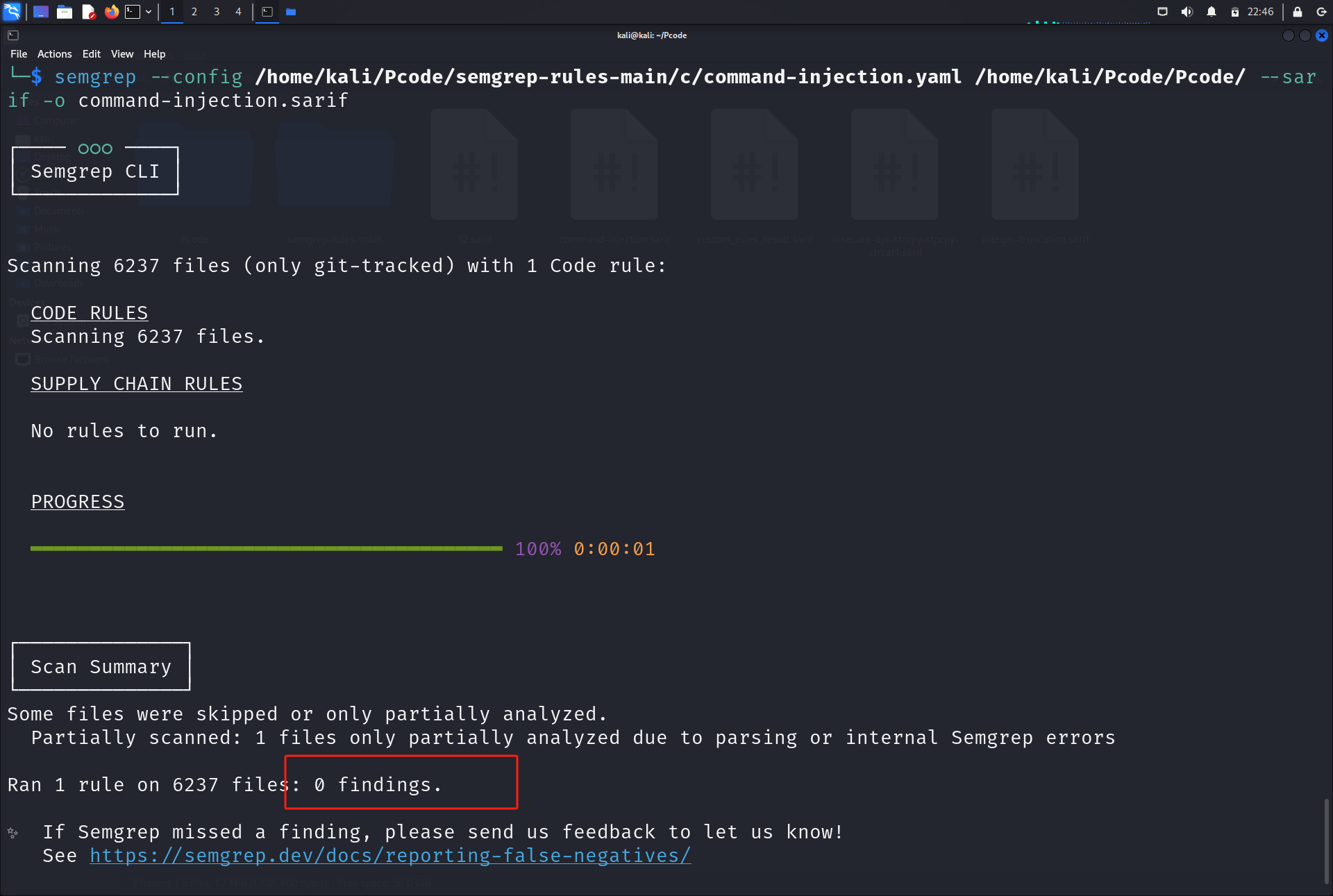
检测机制
1.外部输入影响的命令构造: 规则关注的是程序通过外部输入(例如用户输入、网络请求、环境变量等)来构造和执行操作系统命令(如 system()、popen() 等)。如果这些外部输入没有被正确地净化或过滤,攻击者可能利用恶意输入执行任意操作系统命令。
2.匹配模式:system(…) 和 popen(…):这两个函数分别用于执行操作系统命令和打开进程的管道。这些函数常用于调用系统命令,若传入的参数包含未经过滤的外部输入,可能导致命令注入。
3.排除无关的函数调用:pattern-not: $FUN(“…”, …):此模式排除了包含特定函数调用格式的情形(即 FUN(“…”, …))。这可能是为了避免匹配到某些正常的函数调用,如那些传递硬编码字符串作为参数的调用,而这些调用不涉及外部输入。
2.incorrect-unsigned-comparison 不正确的无符号数比较 自信程度:high
检测机制
1.无符号类型与负数比较:
- 无符号类型的值不能为负数。例如,
unsigned int只能表示 0 或正整数,因此,unsigned int与负数(例如-1)进行比较是没有意义的。在这种情况下,比较会引发不符合预期的行为,甚至可能是程序逻辑的错误。
2.模式匹配: 规则定义了几种可能的无符号类型与负数比较的情况,包括:
unsigned short $UNSIGNED < 0unsigned int $UNSIGNED < 0unsigned long $UNSIGNED < 0size_t $UNSIGNED < 0
这些模式检测了无符号类型与负数进行 < 或 <= 比较的情形。根据 C 和 C++ 语言规范,所有这些比较将始终是 false,因为无符号数永远不可能小于 0。
另外,规则也包括了对无符号类型与 0 的比较:
unsigned short $UNSIGNED <= 0unsigned int $UNSIGNED <= 0size_t $UNSIGNED <= 0
这些比较通常是无意义的,因为它们会总是 true,因为无符号数的范围从 0 开始,而 <= 0 会始终成立。
3.逻辑不正确的比较:
- 对于无符号数与负数的比较,无论是
<还是<=,都没有实际意义,代码中的此类比较通常表明程序员可能犯了逻辑错误,或者误用了数据类型。 - 比较一个无符号数与负数进行
>= 0这样的操作是始终为true的。因为无符号数的最小值为 0,所有的无符号数都大于等于 0。
4.检测逻辑上的错误: 规则的本质是捕捉那些无符号数与负数比较的无效或错误的情况,这些比较通常是由于不正确的假设、错误的数据类型选择或者输入验证的缺失所引起的。这些错误在编译时通常不会报错,但会导致程序在运行时表现出未定义或不符合预期的行为。
3.incorrect-use-of-memset 内存集使用不当 自信程度:high
检测机制
memset()函数:
void *memset(void *s, int c, size_t n);
- 第一个参数
s是指向目标内存区域的指针。 - 第二个参数
c是要设置的值,通常是字符或整数(通常用于设置为某个字节值)。 - 第三个参数
n是要设置的字节数。
如果这些参数的顺序不正确,memset() 调用将不会按预期工作,可能导致内存没有被正确设置或引发其他未定义行为。
4.incorrect-use-of-strncat 自信程度:high
检测机制:
- 传递整个缓冲区的大小
错误地传递缓冲区的总大小而不是剩余的空间大小。eg:
strncat($DST, $SRC, sizeof($DST));
- 使用数组大小来计算可用空间
有时,开发者可能会错误地根据数组的大小而不是剩余空间来设定 strncat() 的第三个参数。
3.使用 strlen() 获取当前字符串长度
错误地使用 strlen() 来计算目标字符串的长度,可能会导致错误的大小传递给 strncat(),尤其是在动态长度字符串的情况下。
- “Off-by-one” 错误
“Off-by-one”错误是另一个常见的问题,尤其是在使用 sizeof($DST) - strlen($DST) 来计算剩余空间时。如果不考虑 NUL 字符的空间需求,可能会将多余的字节写入目标缓冲区,导致溢出。为了避免这种情况,应该传递剩余空间的大小减去 1。正确的使用方式是:
strncat($DST, $SRC, sizeof($DST) - strlen($DST) - 1);
5.insecure-api-access-stat-lstat 自信程度:high
用于检测在 C 和 C++ 代码中对文件或资源的访问与状态检查之间存在竞争条件的情况。
检测机制:
规则通过以下模式检测文件访问和状态检查的潜在 TOCTOU (Time-of-check to time-of-use)漏洞:
access(...)stat(...)lstat(...)
这些模式表示检测到这三种函数调用之一,并评估它们是否被用于检查资源的状态,但在之后没有进行再次检查,从而可能导致资源状态变化后进行不安全的操作。
6.insecure-api-alloca 自信程度:high
检测 C 和 C++ 代码中对 alloca() 函数的使用
7.insecure-api-atoi-atol-atof
用于检测 C 和 C++ 代码中使用了 atoi()、atol()、atof() 等函数。这些函数用于将字符串转换为整数或浮动值,但它们存在一些不安全和不可预测的行为,因此该规则提醒开发者避免使用这些函数。
8.insecure-api-gets
gets() 函数是一个已知的不安全函数,原因在于它不对输入的大小进行边界检查,可能导致缓冲区溢出
参考:cwe-242;cwe-120
9.insecure-api-mktemp-tmpnam-tempnam
mktemp()、tmpnam() 和 tempnam(),这些函数用于生成临时文件名或路径,但存在安全风险。
参考:cwe-377;cwe-367
10.insecure-api-rand-srand
用于检测 C 和 C++ 代码中使用了不安全的伪随机数生成器(PRNG)函数 rand() 和 srand()。这些函数通常用于生成随机数,但它们的随机性较差,不适用于需要高质量随机数的应用。
参考:cwe-338;cwe-330
11.insecure-api-scanf-etc
检测 C 和 C++ 代码中不安全的 scanf() 及其相关函数的使用。这些函数容易引发缓冲区溢出等安全漏洞,主要是因为它们没有内建的缓冲区边界检查。
参考:cwe-676;cwe-120;cwe-787
检测函数:
scanf($FMT, ...)
vscanf($FMT, ...)
fscanf($FS, $FMT, ...)
vfscanf($FS, $FMT, ...)
sscanf($BUF, $FMT, ...)
vsscanf($BUF, $FMT, ...)
wscanf($FMT, ...)
vwscanf($FMT, ...)
fwscanf($FS, $FMT, ...)
vfwscanf($FS, $FMT, ...)
swscanf($BUF, $FMT, ...)
vswscanf($BUF, $FMT, ...)
12.insecure-api-signal
13.insecure-api-sprintf-vsprintf
检查代码中是否使用了 signal() 函数,建议使用 sigaction() 作为替代方案。
参考:cwe-364;cwe-479;cwe-828
14.insecure-api-strcpy-stpcpy-strcat
检测不安全的字符串操作函数,如 strcpy(), stpcpy(), strcat() 等,这些函数没有进行边界检查,容易导致缓冲区溢出。
参考:cwe-676;cwe-120;cwe-787
自信程度:media
integer-truncation(整数截断):1375findings
目的: 识别代码中可能发生整数截断的场景。
问题描述:
- 截断错误发生在将较大整数值赋值给较小类型(如
int转char)时,高位数据可能被丢弃,从而导致数据完整性问题。 - 截断错误的后果可能包括:
- 数据精度丢失。
- 逻辑错误(如溢出或意外的负值)。
- 安全漏洞(例如,值验证失效)。
具体触发条件:
- 涉及的类型转换:
char、short、int、long以及它们的无符号类型。- 例如:
(char $NARROW) = <... (int $LARGE) ...>(short $NARROW) = <... (long $LARGE) ...>
- 函数返回值检查:
- 函数声明返回较小类型,但实际返回语句为较大类型。
- 示例模式:
1 | |
- 特定的场景和排除:
- 使用
pattern-not防止误报。 - 例如,排除字符串的使用(如
sizeof("..."))。
- 使用
interesting-api-calls(敏感api调用):1625findings
pointer-subtraction(指针减法):1findings
double-free
format-string-bugs
incorrect-order-setuid-setgid-etc
incorrect-use-of-free
incorrect-use-of-sizeof
incorrect-use-of-sprintf-snprintf
incorrect-use-of-strncpy-stpncpy-strlcpy
off-by-one
suspicious-assert
unchecked-ret-malloc-calloc-realloc
unchecked-ret-scanf-etc
unchecked-ret-setuid-seteuid
unsafe-ret-snprintf-vsnprintf
unsafe-ret-strlcpy-strlcat
unsafe-strlen
unterminated-string-strncpy-stpncpy
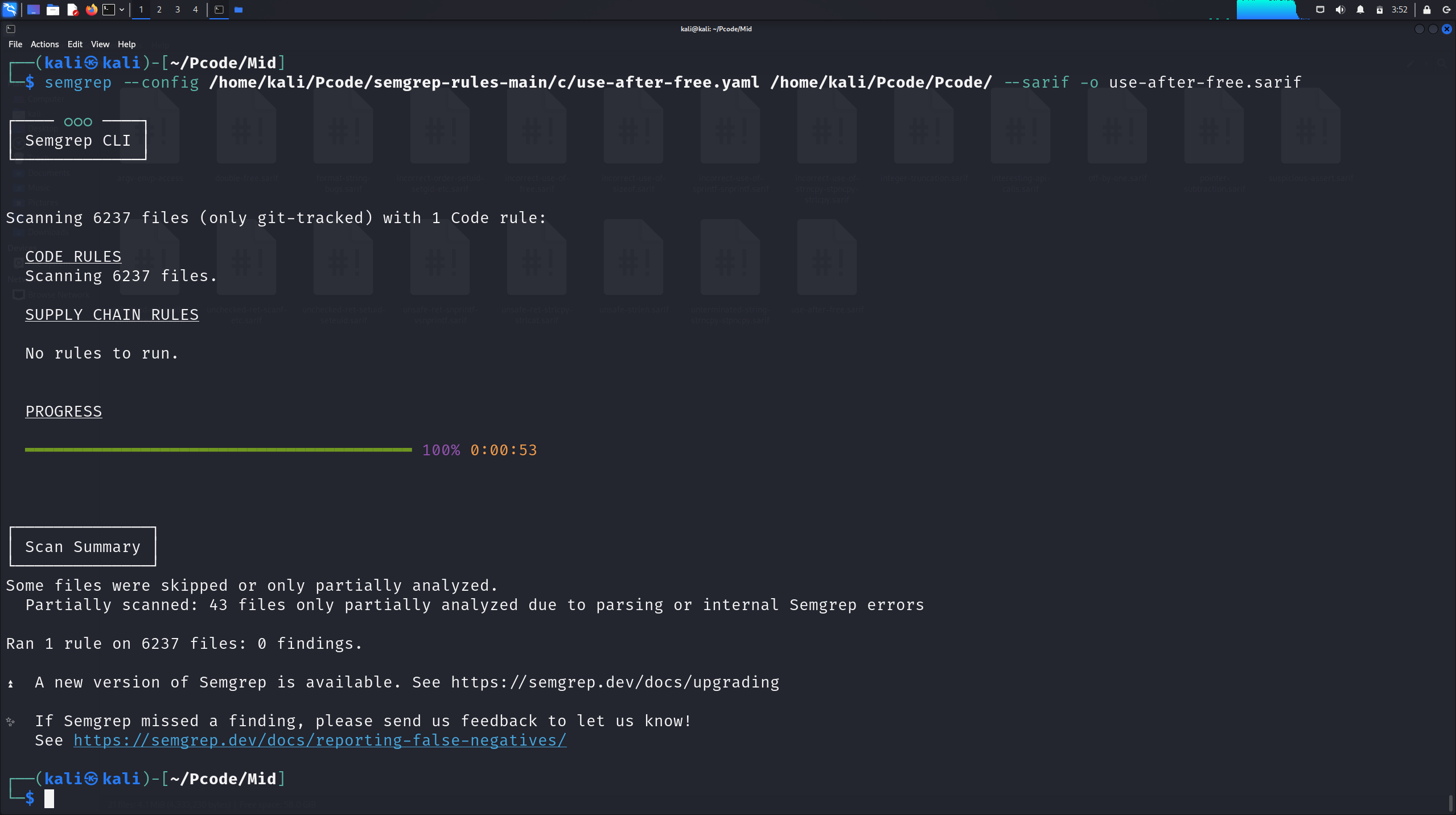
use-after-free
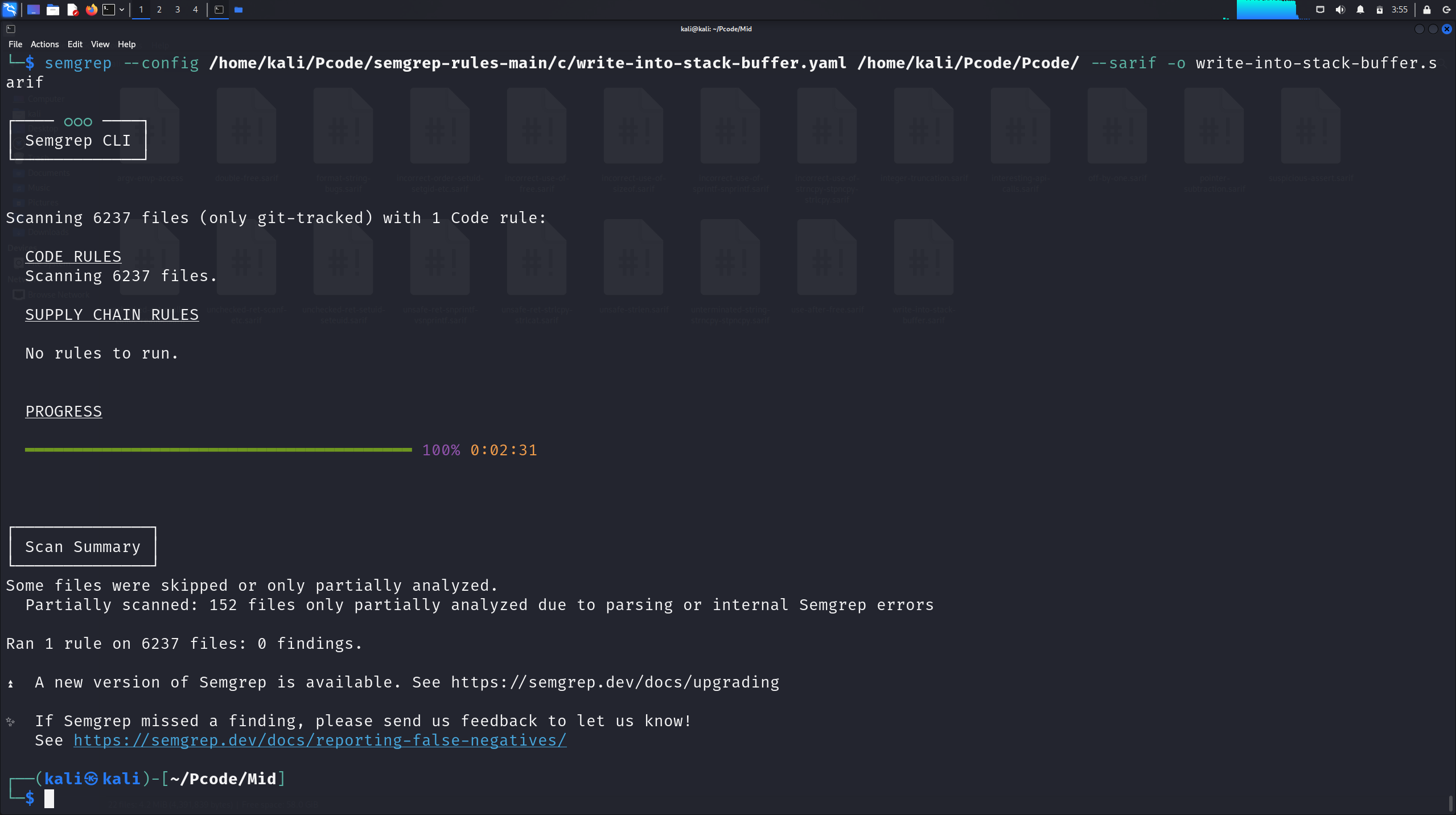
write-into-stack-buffer
脏数据的流程分析–数据输入–相关路径的危险调用
考虑多线程状况下 复杂的脏数据
结果的自动化分析