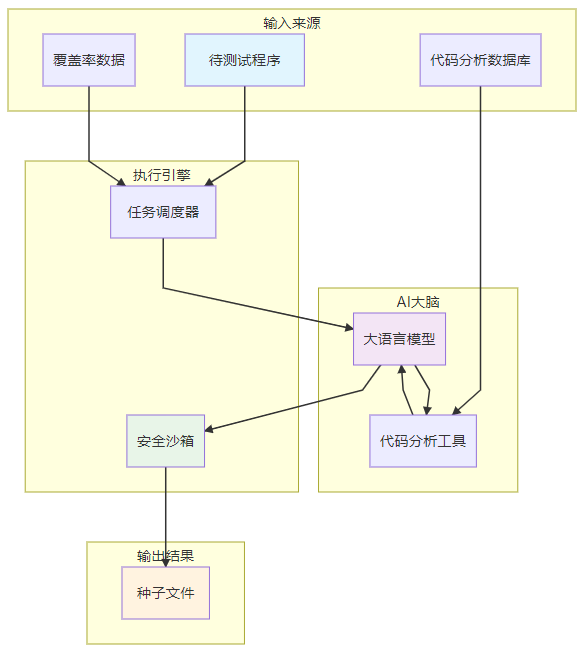
目标:
种子生成拎出来
这个 pod 的输入是什么,输出是什么。
针对协议和内核的 fuzz,py 脚本如何适配
局限性 cwe 效果
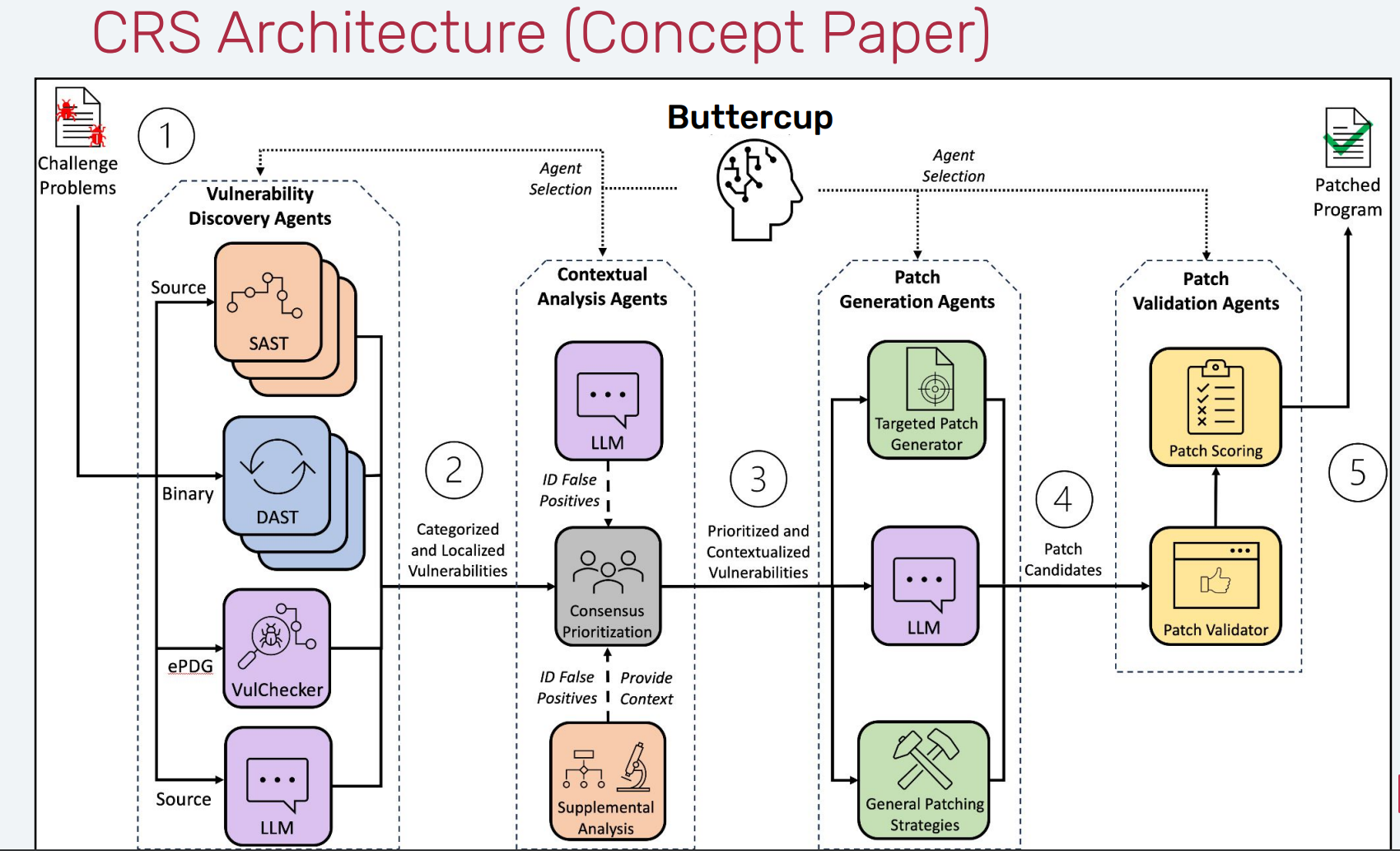
buttercup buttercup 介绍 github 链接:https://github.com/trailofbits/buttercup
介绍链接:https://blog.trailofbits.com/2025/08/08/buttercup-is-now-open-source/?utm_ source=chatgpt.com
介绍 pdf:https://www.trailofbits.com/documents/DEFCON_ AIxCC_ Stage_ Talk.pdf
DEFCON_ AIxCC_ Stage_ Talk.pdf
理想状态:
实际代码实现:
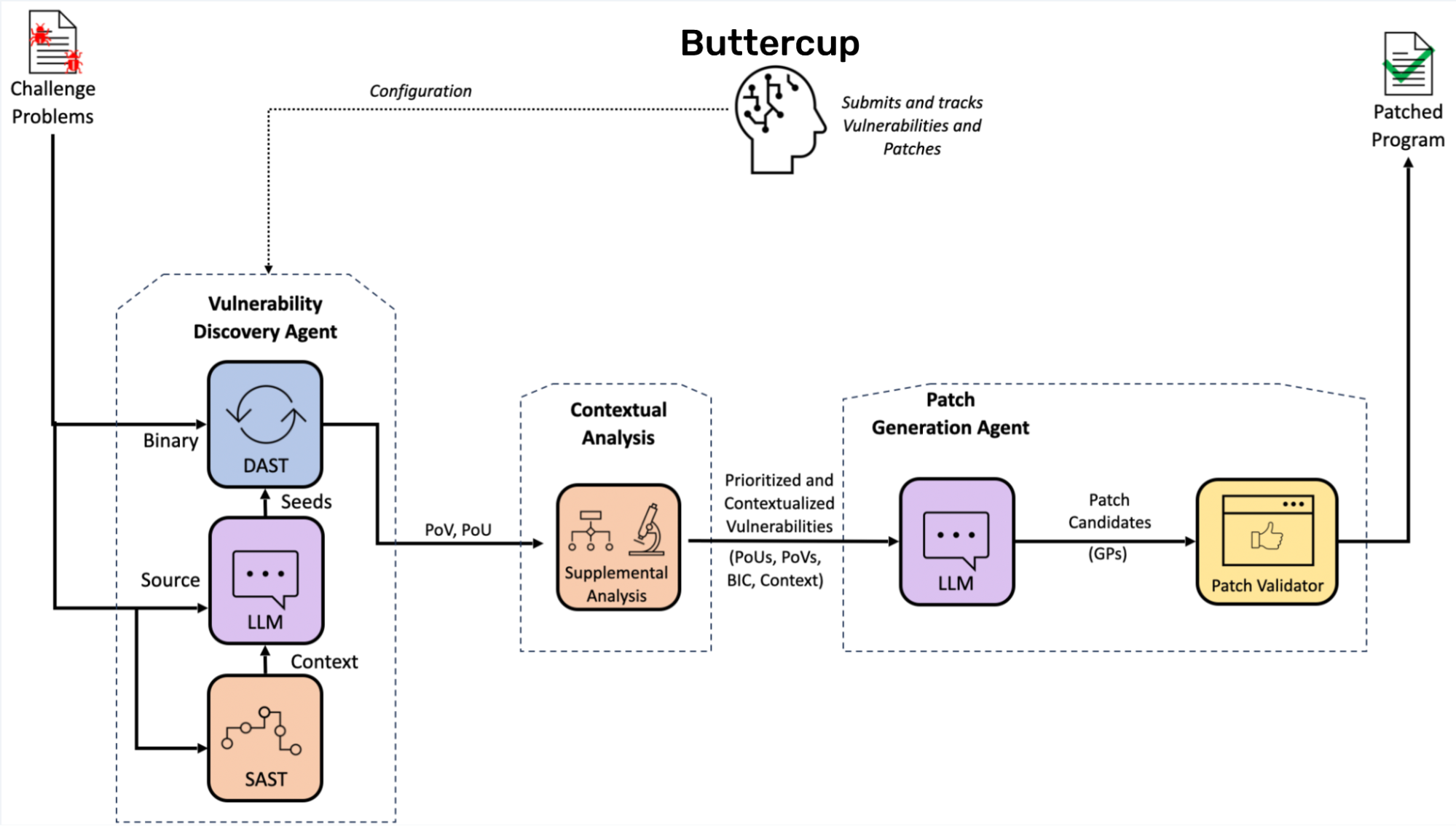
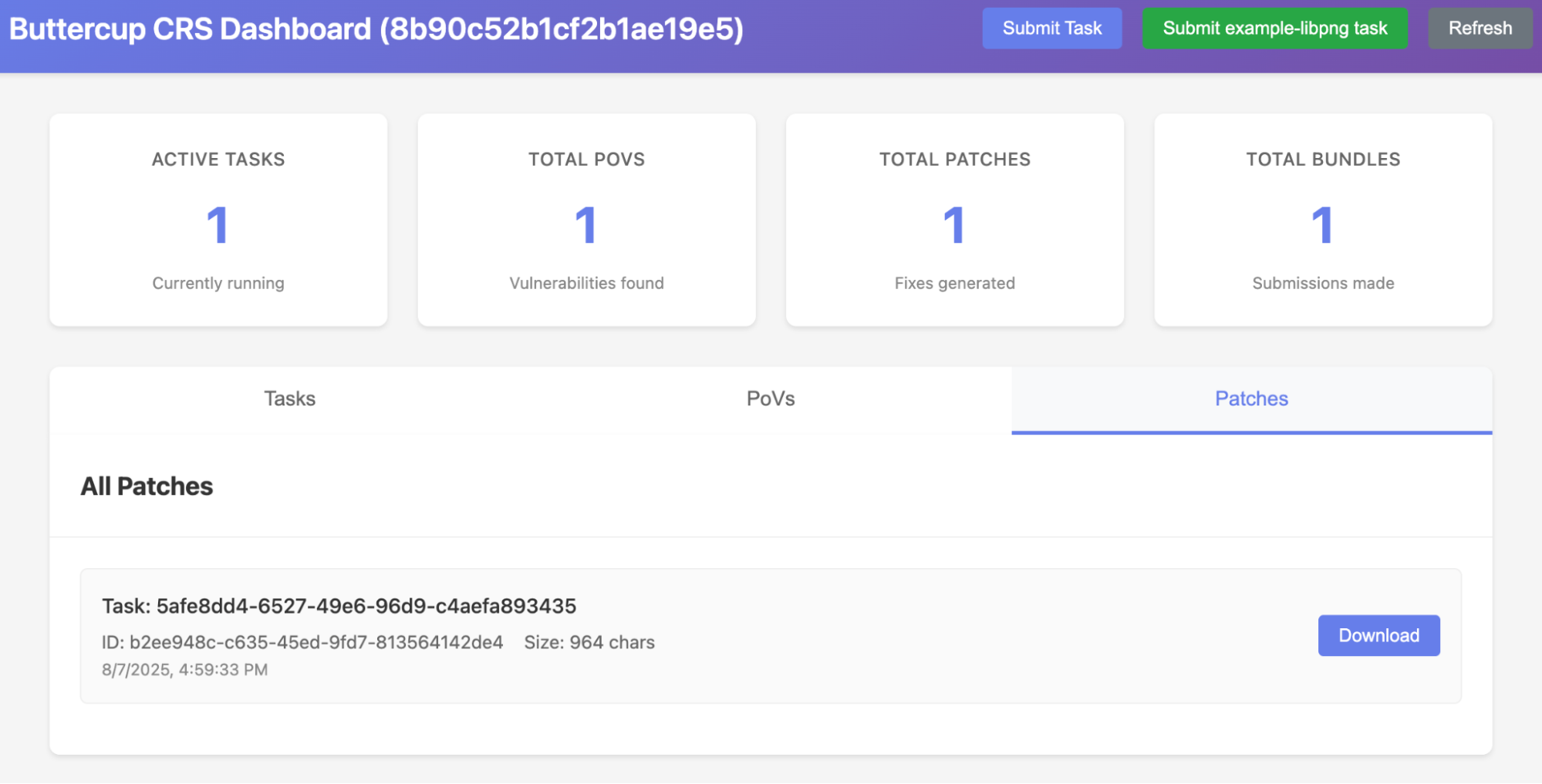
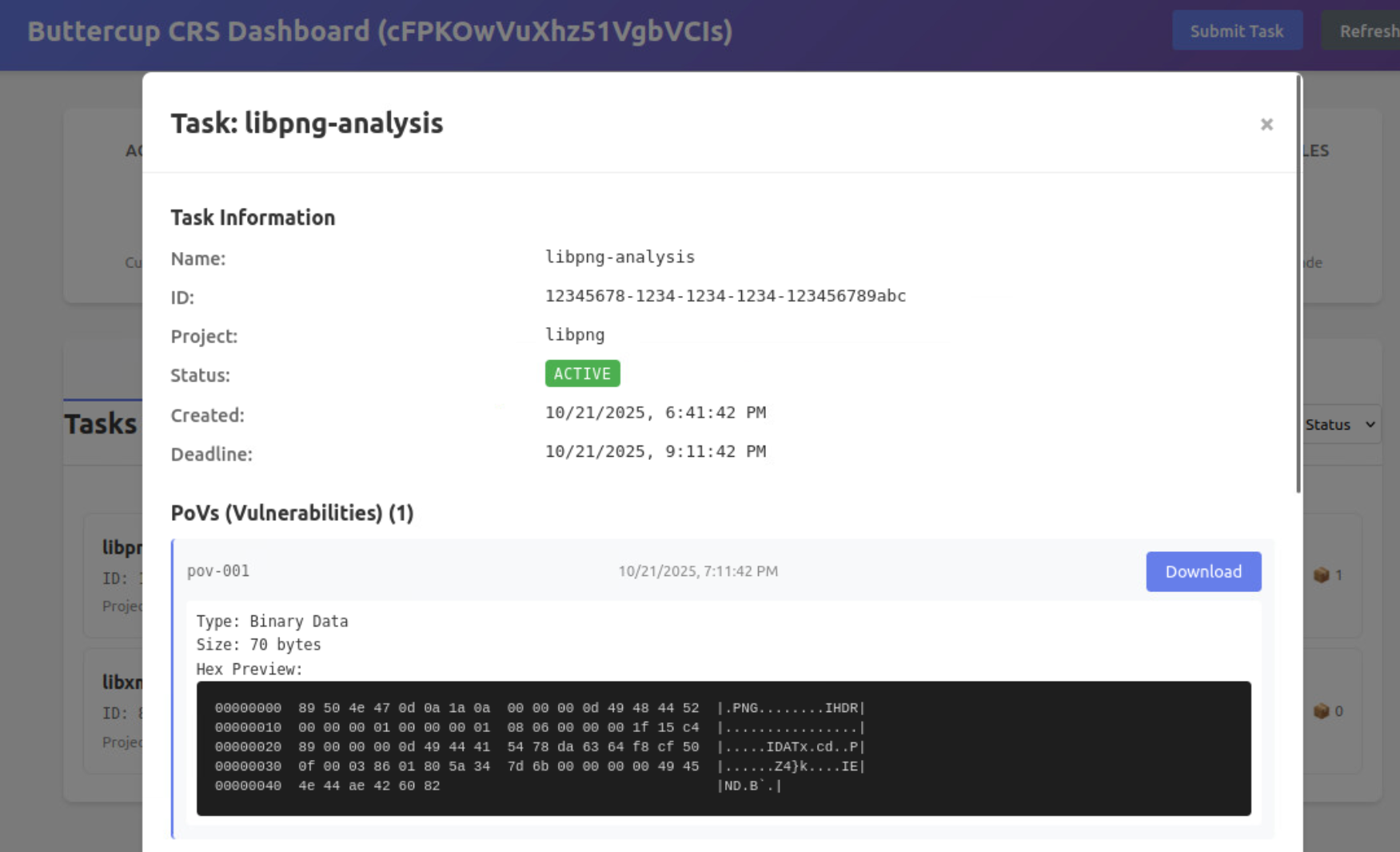
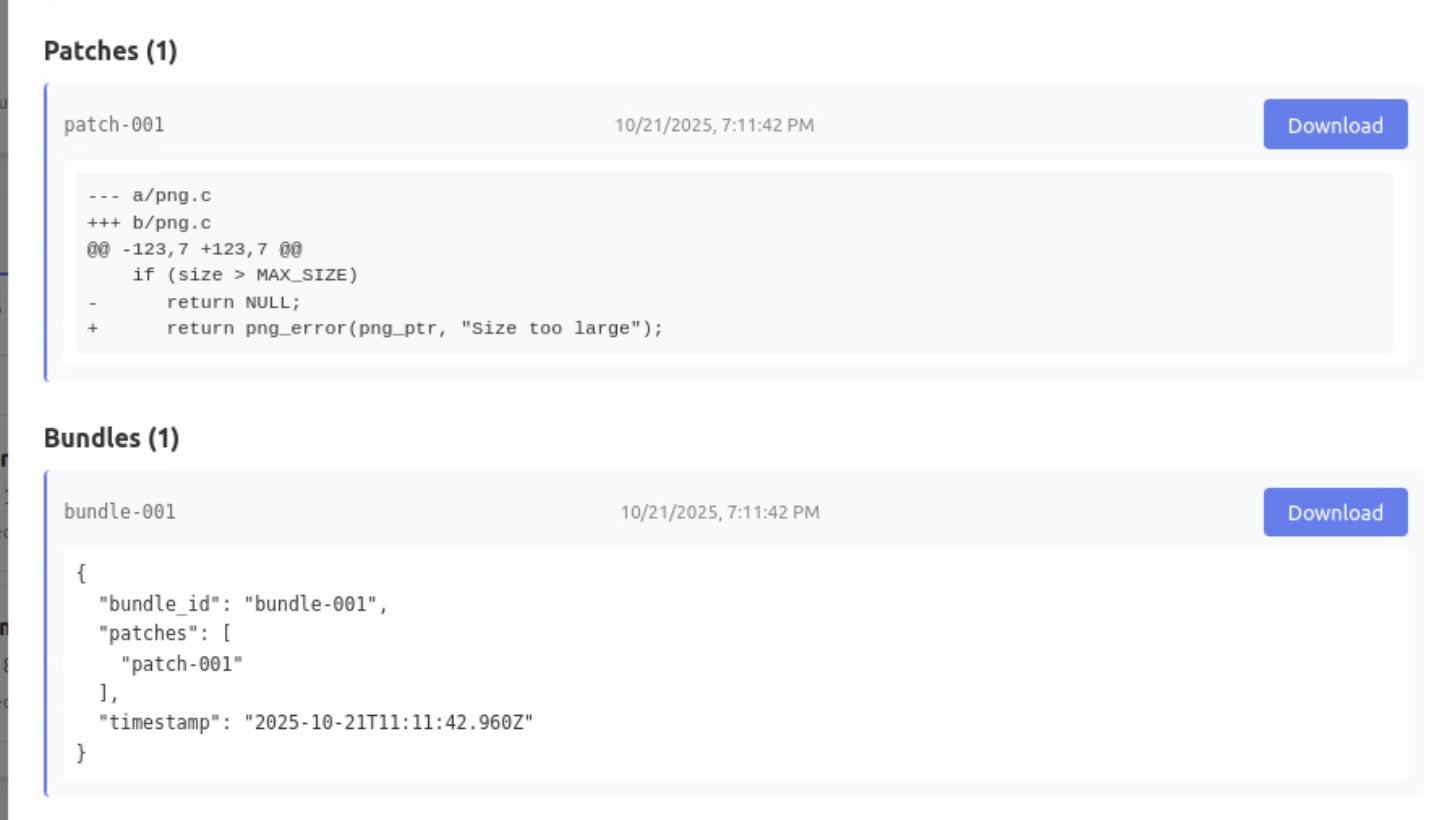
当 Buttercup 启动时,它会以兼容 OSS-Fuzz 的源代码存储库的形式等待用户的任务。一旦完成任务,Buttercup 就会检索代码存储库,在启用和不启用各种清理器的情况下构建程序,并在基于 AI 的输入生成器的帮助下开始模糊测试程序。当输入触发程序中的清理器、超时或崩溃时,这些输入将被记录为漏洞证明 (PoV)。
接下来,Buttercup 的编排器会删除重复的 PoV,并将唯一的崩溃发送到补丁生成系统进行修补。补丁生成系统使用来自上下文分析系统的信息,迭代地创建、测试和完善补丁,直到它生成一个补丁,该补丁 1) 防止 PoV 及其重复触发漏洞,以及 2) 维护程序的其他功能。最后,Buttercup 的编排器会保留 PoV 和补丁,以便可以向用户报告它们。
——–问题: 1.ai 生成了什么?怎么做 fuzz 的
2.生成的 pov 的格式是什么
3.系统如何分析上下文的
4.分析上下文的结果是什么
5.patch 如何生成的,如何进行测试,如何进行完善
杂七杂八 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 (buttercup) buttercup2@buttercup2-virtual-machine:~/AI/AIxCC/buttercup$ cloc .
1 2 ~/AI/AIxCC/buttercup$ docker ps | wc -l
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 ┌─────────────────────────────────────────────────────────────────────────────┐
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 ┌─────────────────────────────────────────────────────────────────┐
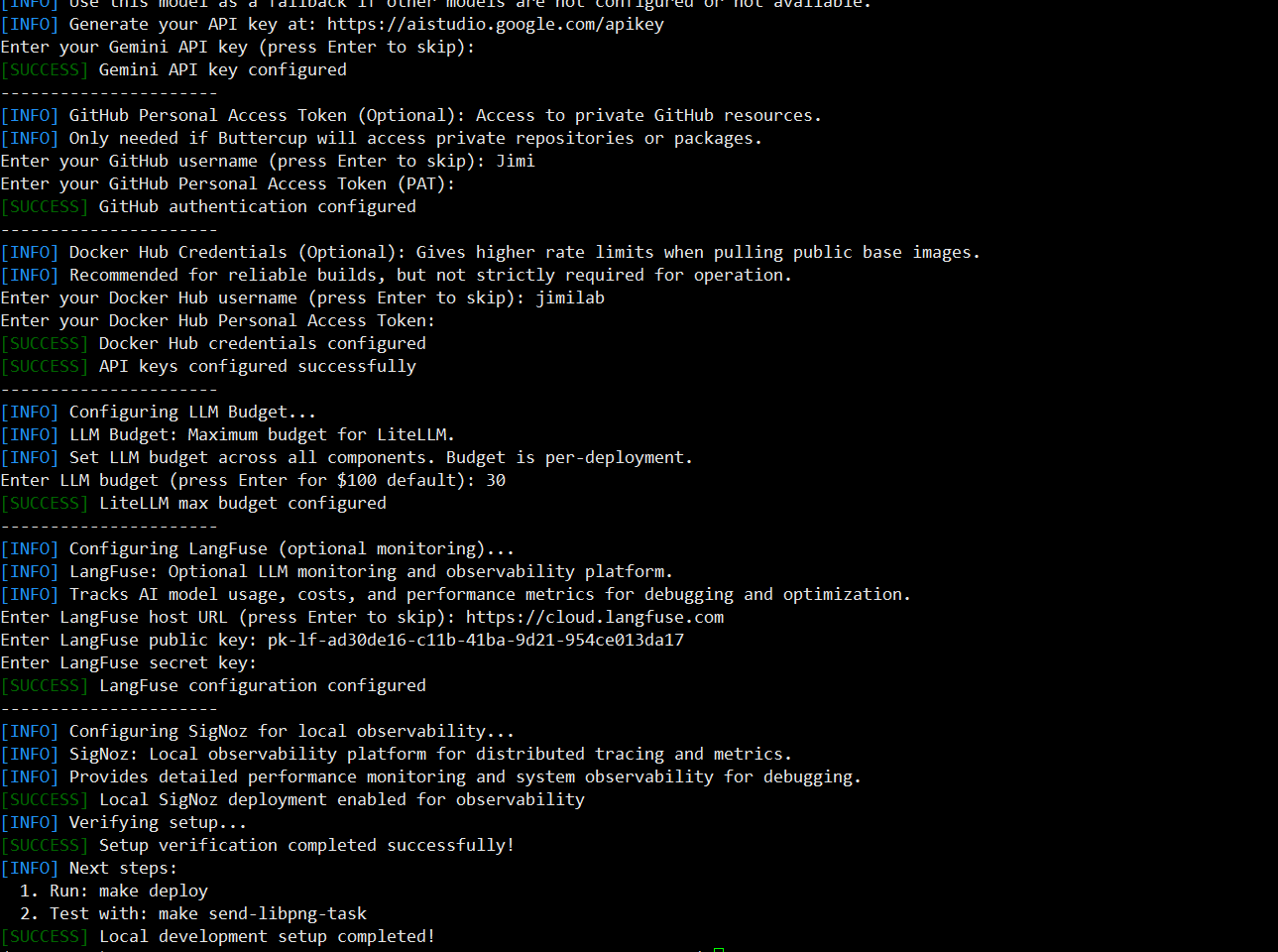
部署流程 环境全新 ubuntu 22.04+miniconda py3.12+梯子
github 下载源码:
make setup-local clash开启了tun模式,为了能ping通docker.io 这样就不用再挂换源了
如果 docker 报错权限不足,将当前用户添加到 docker 用户组
1 sudo usermod -aG docker $USER && newgrp docker
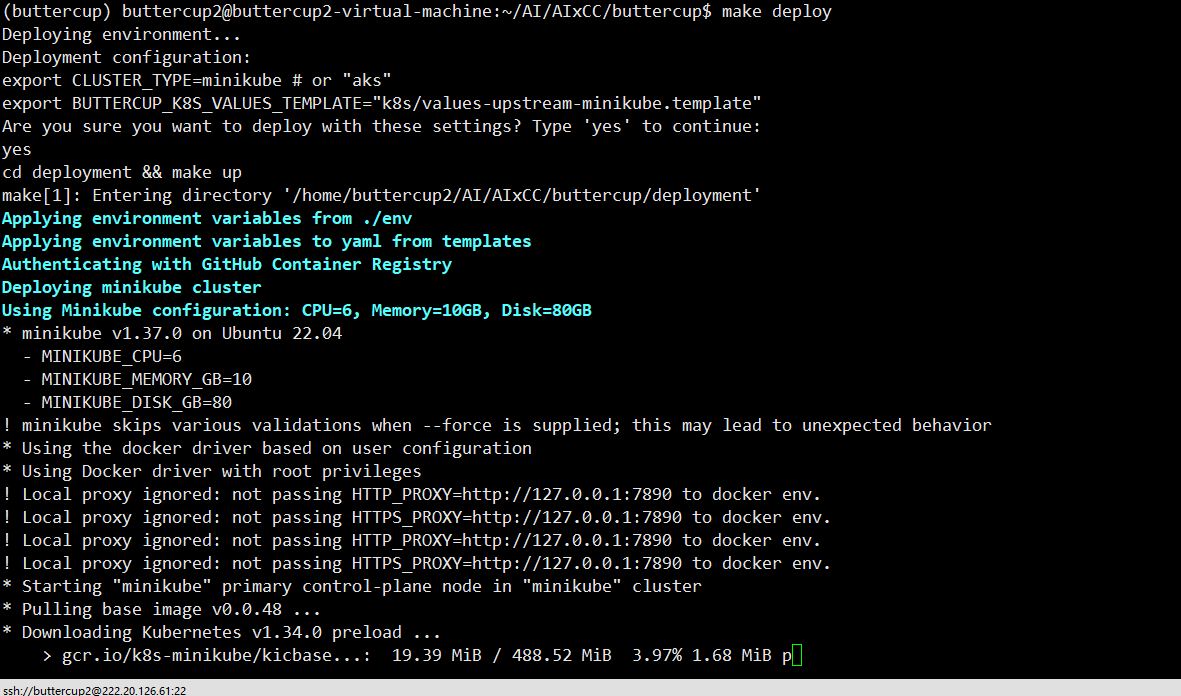
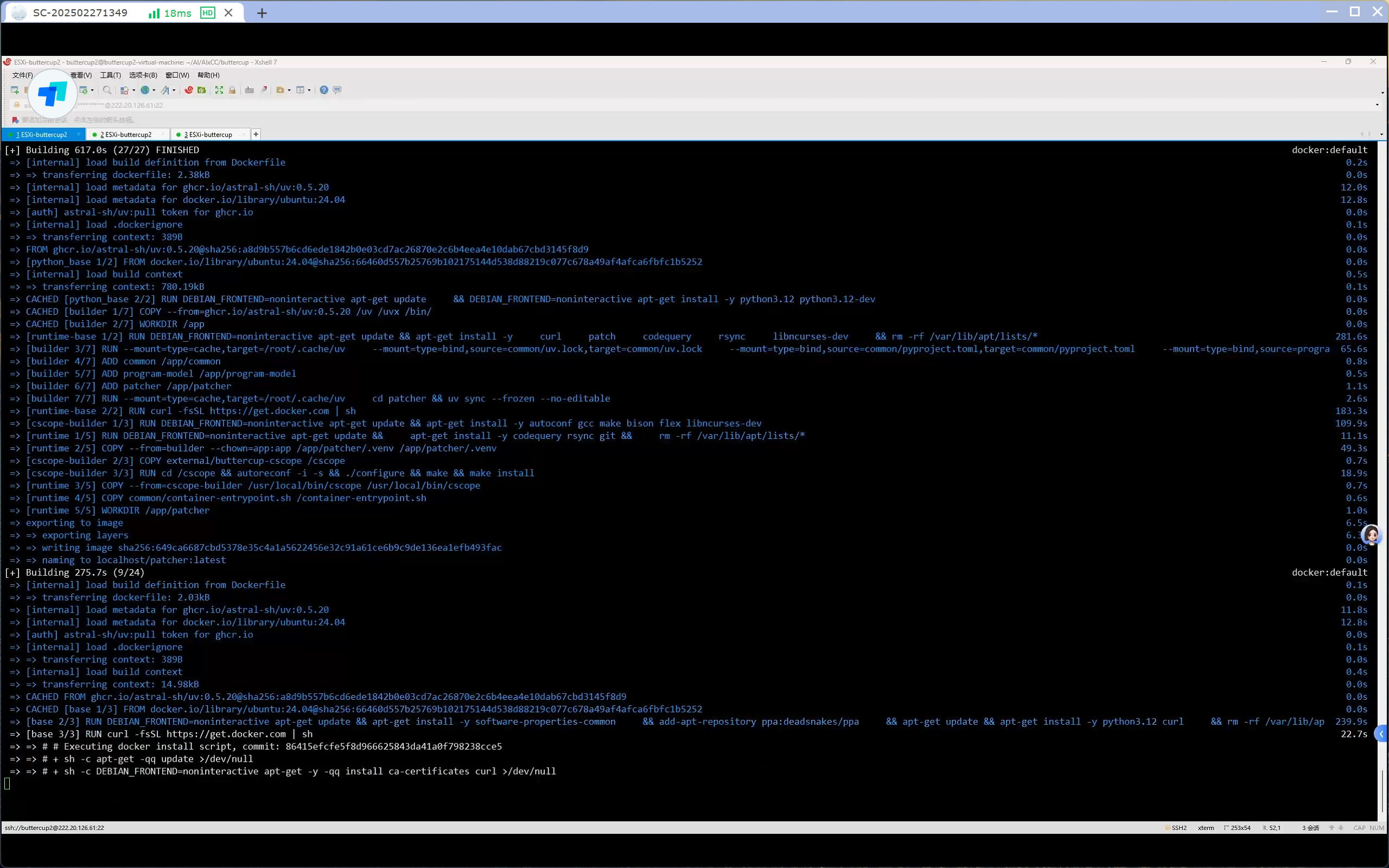
make deploy (时间比较长,而且这一步报错的很多)
该命令实际运行的脚本是:/deployment/crs-architecture.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 make deploy (项目根目录)
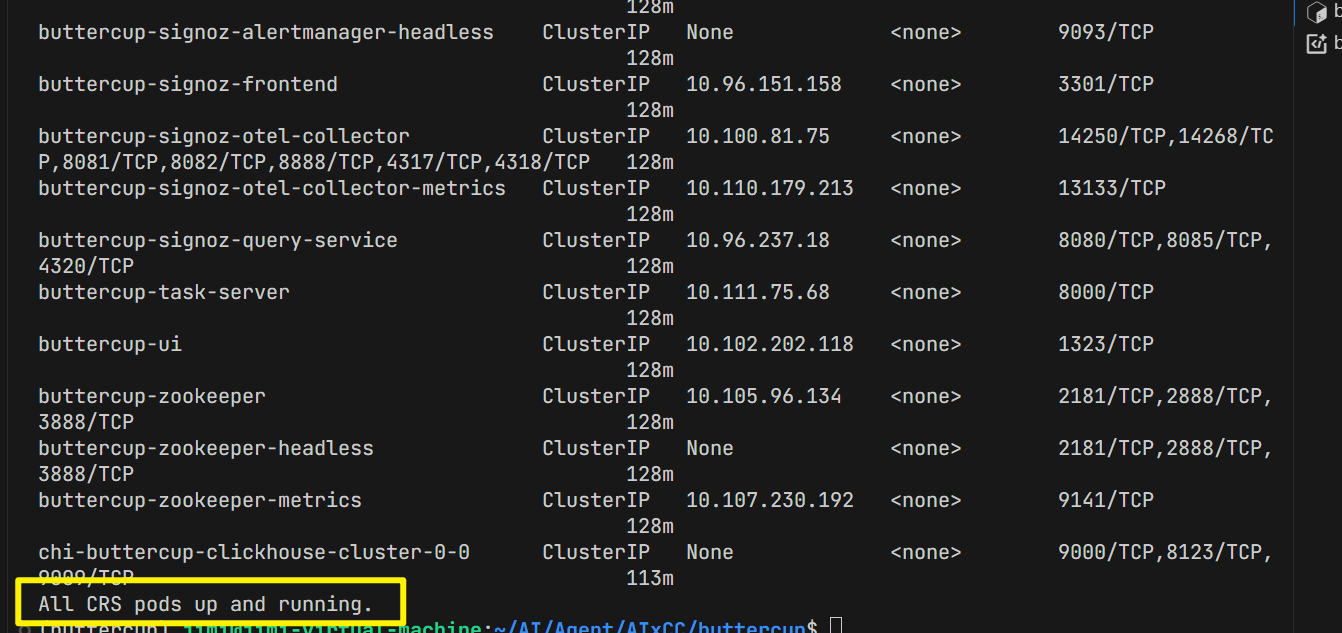
make status 部署成功:需要所有 pods 都成功启动
make send-libpng.sh 运行该命令进行测试
SigNoz 界面:
与 make send-libpng.sh 相同效果的代码:
1 2 3 4 5 6 7 8 一个shell中启动web:
调试命令 make 命令: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 (buttercup) buttercup2@buttercup2-virtual-machine:~/AI/AIxCC/buttercup$ make
kubectl 调试命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 # View all resources
minikube 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # Start/stop
Helm 1 2 3 4 5 6 # Update repositories
Logs analysis 1 2 3 4 5 6 7 8 # check Patch Submission
部署失败解决: 1.send-gen 和 patcher pod 失败
https://github.com/trailofbits/buttercup/issues/315
1 2 Error: UPGRADE FAILED: post-upgrade hooks failed: 1 error occurred:
https://github.com/trailofbits/buttercup/issues/317
使用 项目输入 buttercup 的项目的输入是一个开源的 github 的链接,需要兼容 Oss-Fuzz 的格式。
项目有两个项目输入点:
一个是/orchestrator/scripts/task_upstream_libpng.sh
1 2 3 4 5 6 7 8 9 #!/bin/bash
一个是 web
执行流程 任务提交 运行任务后的执行流程: task_upstream_libpng.sh
1 2 3 4 5 6 7 8 9 #!/bin/bash
通过 curl 向本地 31323 端口发送一个 json 格式的 post 请求, /webhook/trigger_task 路由
buttercup-main\orchestrator\src\buttercup\orchestrator\ui\competition_api\main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @app.post("/webhook/trigger_task")
buttercup-main\orchestrator\src\buttercup\orchestrator\ui\competition_api\services\crs_client.py
1 2 3 4 5 6 7 8 9 10 11 12 submit_task.py
buttercup-main\orchestrator\src\buttercup\orchestrator\task_server\server.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 后端接口
buttercup-main\orchestrator\src\buttercup\orchestrator\task_server\backend.py
1 2 3 4 5 6 7 8 9 10
buttercup-main\orchestrator\src\buttercup\orchestrator\downloader\downloader.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 创建redis队列,获取taskdownload消息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 时间线 组件 操作
程序分析-构建 buttercup-main\orchestrator\src\buttercup\orchestrator\scheduler\scheduler.py
生成 IndexRequest 并写入 INDEX 队列
调用 process_ready_task 生成 BuildRequest 并写入 BUILD 队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # scheduler.py Line 224-262
程序分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 # program_model.py Line 59-95
tree-sitter Tree-sitter 由 CodeTS 封装,负责加载不同语言的解析器与查询模板,并将源码字节解析成结构化的Function与TypeDefinition对象。Tree-sitter.py的输入是code和file_path,其中code指传入的源代码内容,file_path指文件路径,tree-sitter的输出是结构化的Function(函数)与TypeDefinition(类型定义),最终以字典形式返回。
整体的目标为: (以函数为例)
CodeTS.get_function(function_name, file_path) 负责在指定文件里解析源码,找到名称匹配的函数,并返回封装好的 Function 对象(含所有候选函数体)。
执行步骤为:
入口 get_function 首先调用 get_functions(file_path),也就是对整个文件做一次函数扫描。
get_functions 读取目标文件的字节内容 code,交给核心逻辑 get_functions_in_code(code, file_path)。
get_functions_in_code 根据语言类型选用 code 或剔除预处理指令后的 code_no_preproc,然后调用 tree-sitter parser 生成
tree = self.parser.parse(…)
,取root_node。
事先构建好的 self.query(Tree-sitter Query)在 root_node 上执行 matches,产出所有函数定义的 capture 集。每个 capture 会包含函数名、定义范围、函数体等信息(如果命中宏模式,也会带
macro.call
标记)。
取出 function.definition / function.name / function.body节点,判断是否为宏展开;
根据节点的 start_byte / end_byte、start_point / end_point,在原字节串里切出函数体文本,计算 1-based 行号范围;
用 FunctionBody 和 Function dataclass 组装好函数记录,并按函数名塞进 functions 字典;若同名函数有多个体(例如 #ifdef 分支),都会保留。
全部遍历后返回 dict[str, Function]。
get_function 再从该字典中 functions.get(function_name),拿到匹配的 Function;如果没找到就返回 None。
codequery codequery可以为“挑战项目(ChallengeTask)”在OSS-Fuzz 容器视角 下建立代码索引(cscope/ctags/CodeQuery),并提供函数/类型的精确与模糊检索 、调用者/被调者关系 、类型使用位置 等能力。
核心的工作流程如下:
初始化(__post_init__)
检查依赖命令。
建立 Tree-sitter 解析器 CodeTS。
读项目语言(通过 ProjectYaml),选择对应的模糊导入解析器 。
若索引已存在(四件套:cscope.files/cscope.out/tags/codequery.db),直接复用;否则:
要求 ChallengeTask 为可写(否则抛错)。
触发 _create_codequery_db():复制容器 /src、生成 cscope 列表、跑 cscope/ctags/cqmakedb 构建数据库。
索引构建(_create_codequery_db)
docker cp <container>:/src -> <task_dir>/container_src_dir按语言(C/C++ 或 Java)收集扩展名列表,递归写入 cscope.files
cscope -bkq → ctags --fields=+i -n -L cscope.files → cqmakedb 将 cscope.out+tags合并为 codequery.db每步都容错并显式校验产物是否存在,失败即抛错。
路径重映射
_rebase_path():把<task_dir>/container_src_dir/...重映射为容器视角/src/...(对外返回统一容器绝对路径)。_rebase_*_file_paths():把函数/类型/类型使用信息中的文件路径统一重映射。
通用查询子程序
_run_cqsearch(*args):封装 cqsearch 调用与结果解析为 CQSearchResult。
函数检索(get_functions)
思路:先用 cqsearch 的 符号 (-p 1)与 函数 (-p 2)两种模式取候选,再用 CodeTS.get_function()做 AST 级别精确解析,最终返回 Function 对象(可能有多个 body 区块)。
支持:
限定文件与行号(用于 disambiguation)。
模糊检索(可选,没给文件时才启用):对全局函数表跑 rapidfuzz 相似度过滤,再按相似度降序追加候选。
结果排序:保持与 cqsearch 的返回顺序一致(先 exact 再 fuzzy)。
Telemetry:把函数名、是否 fuzzy、文件、行号等写进 span 属性。
调用者(get_callers)
用 -p 6(“函数的调用者”)在 db 中查到调用者的函数定义名 及其位置,再对每个结果调用 get_functions,转为结构化 Function。
可能是超集 (因为没法限定“在具体行号定义的那个 f 的调用者”),返回前不过滤 。
被调者(get_callees)
先用 get_functions 定位精准的函数定义 (获取其一个或多个 body 的起止行)。
用 -p 7 查询调用点 (注意:返回的是“调用发生的行”,不是被调者的定义)。
只保留:文件路径匹配、且调用行号落在该函数 body 范围内的调用点。
对每个调用点再 get_functions(result.value) 找到被调者的定义 。
最后可选用 imports_resolver.filter_callees() 按导入/包/包含关系过滤(减少跨库同名误配)。
仍可能是超集 (database 粒度限制),但已经借助 AST 与行号做了较强过滤。
类型定义与使用(get_types / get_type_calls)
get_types:用 -p 1(符号)+ -p 3(class/struct)搜候选,再交给 CodeTS.parse_types_in_code(file, typename, fuzzy) 做精解析,得到 TypeDefinition(包含定义行、原始定义文本、文件等)。
可指定 function_name,则只保留落在该函数体范围内的局部类型定义 (如局部 typedef/struct)。
亦支持 fuzzy(无 file_path 时)。
get_type_calls:以 type_definition.name 用 -p 1+-p 8(类型使用点)搜,返回 TypeUsageInfo(文件、行号)。
编译构建 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 # scheduler.py Line 160-194
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 # builder_bot.py Line 98-145
种子生成
FUZZ 崩溃分析
漏洞验证
漏洞补丁阶段
1.定位漏洞
2.提取并压缩上下文
3.生成补丁
4.补丁筛除
AI 的应用 1.AI 优化种子的生成 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 阶段 1: Fuzzer 构建
第一步:Fuzzer 构建流程 1.1 Scheduler 发起构建请求
1 2 3 4 5 6 7 8 9 for build_req in self .process_ready_task(task_ready.task):self .build_requests_queue.push(build_req)f"[{task_ready.task.task_id} ] Pushed build request of type " f"{BuildType.Name(build_req.build_type)} | {build_req.sanitizer} | " f"{build_req.engine} | {build_req.apply_diff} " ,
构建类型包括:
COVERAGE: 用于覆盖率分析的构建FUZZER: 用于 fuzzing 的构建(ASAqN/UBSAN)TRACER_NO_DIFF: 用于调试的构建
1.2 Builder Bot 处理构建请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def serve_item (self ) -> bool :self ._build_requests_queue.pop()self .python)with origin_task.get_rw_copy(work_dir=self .wdir) as task:if msg.apply_diff:self ._build_outputs_queue.push(BuildOutput(...))
关键操作:
使用 OSS-Fuzz helper.py 构建 Docker 镜像
在 Docker 容器中编译 fuzzer 二进制
编译目标:生成带 sanitizer 的 fuzzer 可执行文件
1.3 构建完成后的触发
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def process_build_output (self, build_output: BuildOutput ) -> list [WeightedHarness]:"""Build output 完成后提取 fuzz targets""" if build_output.build_type != BuildType.FUZZER:return []return [1.0 ,for tgt in targets
WeightedHarness 发布到 HARNESS_MAP → 触发 Fuzzer Bot 和 SeedGenBot
第二步:种子生成的触发 2.1 SeedGenBot 监听构建完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def run_task ( self, task: WeightedHarness, builds: dict [BuildTypeHint, list [BuildOutput]], None :"""当 fuzzer build 完成后,SeedGenBot 被触发""" 0 ].task_dir)with ro_challenge_task.get_rw_copy(work_dir=temp_dir) as challenge_task:self .wdir)self .sample_task(task, is_delta)if task_choice == TaskName.SEED_INIT.value:
2.2 任务选择的逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 def sample_task (self, task: WeightedHarness, is_delta: bool ) -> str :"""根据执行次数选择任务""" self .task_counter.get_count(if seed_init_count < self .MIN_SEED_INIT_RUNS: return TaskName.SEED_INIT.value if vuln_discovery_count < self .MIN_VULN_DISCOVERY_RUNS:return TaskName.VULN_DISCOVERY.valueif is_delta:0.05 ), 0.45 ), 0.50 ), else :0.05 ), 0.35 ), 0.60 ), return random.choices(tasks, weights=weights, k=1 )[0 ]
任务类型解释:
SEED_INIT : 使用 AI 生成初始种子(本文重点)VULN_DISCOVERY : 使用 AI 针对性发现漏洞SEED_EXPLORE : 基于覆盖率扩展种子
第三步:AI 生成种子的详细过程 3.1 SeedInitTask 初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @dataclass class SeedInitTask (SeedBaseTask ):8 4 def do_task (self, output_dir: Path ) -> None :"""执行种子生成任务""" self .get_harness_source()self .generate_seeds(harness, output_dir)
3.2 核心流程:AI 多步骤生成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def generate_seeds (self, harness: HarnessInfo, output_dir: Path ) -> None :"""使用 LangGraph 多步骤生成种子""" self , "" , 0 , self ._build_workflow(BaseTaskState)compile ().with_config("seed-init" ], callbacks=llm_callbacks),
3.3 工作流节点定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def _build_workflow (self, state_class ):"""构建多步骤工作流""" "get_context" , self ._get_context_node)"generate_seeds" , self ._generate_seeds_node)"execute_seeds" , self ._execute_seeds_node)return workflow
3.4 节点 1: 获取上下文(AI 工具调用)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def _get_context (self, state: BaseTaskState ) -> Command:"""使用 AI Agent 检索代码上下文""" "harness" : str (state.harness),"retrieved_context" : state.format_retrieved_context(),self ._get_context_base(return res
AI 可以使用以下工具:
1 2 3 4 5 6 7 8 9 self .tools = [
3.5 Prompt 示例
系统提示词:
1 2 3 4 5 6 7 8 SEED_INIT_GET_CONTEXT_SYSTEM_PROMPT = """ You are an expert security engineer who is creating seed inputs for a fuzzing corpus. Your task is to retrieve relevant code that will help you create high-quality inputs. You have access to tools that can retrieve code from the project. Use these tools to retrieve context about the program. """
用户提示词:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 SEED_INIT_GET_CONTEXT_USER_PROMPT = """ Retrieved context about the codebase: <retrieved_context> {retrieved_context} # 已检索的代码片段 </retrieved_context> The harness is: {harness} # Harness 代码 Your goal is to retrieve additional code that will help create high-quality seeds. When making a tool call: 1. Focus on code that processes or validates inputs 2. Look for code that defines the expected input format or structure 3. You can use the batch tool to make several tool calls in one call. Your response: """
3.6 AI Agent 的工作示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 """ int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) { // Parse PNG header png_structp png_ptr = png_create_read_struct(...); png_infop info_ptr = png_create_info_struct(...); // Read PNG data png_read_info(png_ptr, info_ptr); // ... more processing ... return 0; } """ "这个 harness 调用 png_read_info 解析 PNG 数据。 我需要了解: 1. png_read_info 的实现 2. PNG 文件格式 3. 如何构造有效的 PNG 数据" "png_read_info" )"png_struct" )"png_create_read_struct" )
3.7 节点 2: 生成种子函数(LLM 生成代码)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def _generate_seeds (self, state: BaseTaskState ) -> Command:"""生成种子函数""" "count" : self .SEED_INIT_SEED_COUNT, "harness" : str (state.harness),"retrieved_context" : state.format_retrieved_context(), self ._generate_python_funcs_base(return Command(update={"generated_functions" : generated_functions})
生成提示词:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 PYTHON_SEED_INIT_SYSTEM_PROMPT = """ You are an expert security engineer who is fuzzing a program via a test harness. Write python functions to create seeds that bootstrap the fuzzer's corpus. """ """ Retrieved context about the codebase: <retrieved_context> {retrieved_context} </retrieved_context> The harness is: {harness} You are creating seed inputs to bootstrap the fuzzing corpus. You are provided: 1. Retrieved context about the codebase 2. The harness code Write {count} deterministic Python functions that each create a valid input. Put the functions in ONE MARKDOWN BLOCK. The signature: def gen_test() -> bytes Example output for an FTP server harness: <example> def gen_bytes_user() -> bytes: # user command username = "anonymous" user_cmd = "USER %s\r\n" % (username) return user_cmd.encode() def gen_bytes_pass() -> bytes: # pass command password = "mypassword" pass_cmd = "PASS %s\r\n" % (password) return pass_cmd.encode() </example> Remember: - The functions must create a deterministic sequence of bytes. - A valid input is one that does not cause an error. - Create inputs that trigger different functionality. - Each function creates a different input. """
3.8 LLM 生成的示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def gen_png_minimal () -> bytes :"""Generate a minimal valid PNG file""" b'\x89PNG\r\n\x1a\n' '>2I5B' , 1 , 1 , 8 , 2 , 0 , 0 , 0 )b'IHDR' + ihdr_data0xffffffff '>I' , len (ihdr_data)) + ihdr + struct.pack('>I' , ihdr_crc)'>I' , 0 ) + b'IEND' + struct.pack('>I' , 0xae426082 )return png_signature + ihdr_chunk + iend_chunkdef gen_png_with_palette () -> bytes :"""Generate a PNG with palette""" return png_bytes
3.9 节点 3: 执行种子函数(WASM 沙箱)
1 2 3 4 5 6 def _execute_python_funcs (self, state: BaseTaskState ) -> None :"""在沙箱中执行 Python 函数""" "Executing python functions" )
沙箱执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def sandbox_exec_funcs (functions: str , output_dir: Path ) -> None :"""在 WASI 沙箱中执行函数""" with tempfile.TemporaryDirectory() as workdir:"func.py" for pov_file in wasm_outdir.iterdir():if pov_file.is_file():
沙箱运行器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def exec_seed_funcs (seed_func_path: Path, output_dir: Path ) -> None :"""执行种子函数并保存种子文件""" for func_name, func in inspect.getmembers(module, inspect.isfunction):try :f"Executing function: {func_name} " )f"{func_name} .seed" with open (path, "wb" ) as f:except Exception as e:f"Error occurred: {e} " )
第四步:种子的验证与使用 4.1 复制种子到语料库
1 2 3 4 "Copied %d files to corpus %s" , len (copied_files), corp.corpus_dir)
4.2 Fuzzer Bot 使用种子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def run_task (self, task: WeightedHarness, builds ):"""启动 fuzzer,使用生成的种子""" self .wdir, task.task_id, task.harness_name)self .challenge.run_fuzzer("libfuzzer" ,"address" ,f"-max_len={MAX_LENGTH} " ,f"-timeout={TIMEOUT} " ,
2.AI 驱动的上下文检索 在本项目中上下文检索的应用场景是补丁生成。
作用 1: 智能代码检索(Intelligent Code Search)
不是简单的 grep 搜索,而是让 LLM 分析漏洞,主动决定需要哪些代码。
作用 2: 上下文压缩(Context Compression)
将 50,000+ 行代码压缩到 8,000 tokens 的相关片段,节省 LLM 成本,提高补丁质量。
作用 3: 增量检索(Incremental Retrieval)
根据初步分析结果,逐步请求更多相关的代码片段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 ┌─────────────────────────────────────────────────────────────┐
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 @dataclass class ContextRetrieverAgent (PatcherAgentBase ):"""AI Agent 控制代码检索""" None bool def __post_init__ (self ):self .llm = create_default_llm(model_name=ButtercupLLM.OPENAI_GPT_4_1_MINI.value)self .tools = [self .agent = create_react_agent(self .llm,self .tools,self ._prompt,
实现流程 场景示例:修复 buffer overflow 漏洞 输入:崩溃堆栈跟踪
1 2 3 heap-buffer-overflow in png_read_row
阶段 1: 初始代码请求提取 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def _get_code_requests_from_stacktrace (self, stacktraces, configuration ):"""从堆栈跟踪提取代码请求""" for frame in stackframesif frame.function_name for (func_name, filename), group in groupby(requests_data):f"Implementation of `{func_name} ` in `{filename} `" return requests
LLM 输出:
1 2 <request > Implementation of `png_read_row` in `src/png.c` around line 1234</request >
阶段 2: AI Agent 执行代码检索 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def process_request (self, challenge_task_dir, relevant_code_snippets, request, configuration ):"""处理单个代码请求""" if self .is_code_snippet_already_retrieved(relevant_code_snippets, request):"Code snippet for '%s' already retrieved" , request.request)return []"request" : request.request,"challenge_task_dir" : challenge_task_dir,"work_dir" : configuration.work_dir,self .agent.invoke(self .agent.get_state().valuesreturn ctx_state.code_snippets
AI Agent 的 ReAct 循环 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 while not solved:"Need to find png_read_row function..." )"png_read_row" , "src/png.c" )if result:"Got the function. Now need to check who calls it..." )"png_read_row" )"png_read_row implementation with callers" )
阶段 3: 工具实现详解 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @tool def get_function (function_name: str , file_path: str | None , state: BaseCtxState ) -> str :"""获取函数定义""" if not functions:True )return format_function_code(functions)
CodeQuery SQL 查询:
1 2 3 SELECT name, file_path, start_line, end_line, bodyFROM functionsWHERE name = 'png_read_row' AND file_path = 'src/png.c'
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <command_output > <command > get_function png_read_row src/png.c</command > <returncode > 0</returncode > <stdout > </stdout > </command_output >
1 2 3 4 5 6 7 8 9 10 11 @tool def get_callers (function_name: str , state: BaseCtxState ) -> list [str ]:"""查找谁调用了这个函数""" return [caller.name for caller in callers]
SQL 查询:
1 2 3 SELECT DISTINCT fc.caller_name, fc.caller_fileFROM function_calls fcWHERE fc.callee_name = 'png_read_row'
输出:
1 ["png_read_image", "png_process_row"]
1 2 3 4 5 6 7 8 9 10 11 12 @tool def grep (pattern: str , file_path: str | None , state: BaseCtxState ) -> str :"""全文搜索""" "grep" , "-C" , "5" , "-nHrE" , pattern]if file_path:return format_grep_output(grep_cmd_res)
调用示例:
1 grep("PNG_BUFFER_SIZE" , "src/" )
输出:
1 2 3 src/png.c:100: #define PNG_BUFFER_SIZE 1024
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 @tool def track_snippet ( file_path: str , code_snippet_description: str , function_name: str | None , type_name: str | None , start_line: int | None , end_line: int | None , *, state: CodeSnippetManagerState, tool_call_id: str , """记录代码片段""" if function_name:elif type_name:elif start_line and end_line:True return Command(update={"code_snippets" : [snippet]})
阶段 4: LLM 驱动的上下文需求分析 AI Agent 完成初步检索后,LLM 会分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def get_initial_context (self, state, config ):"""获取初始上下文""" self .initial_snippets_chain.invoke({"STACKTRACES" : state.stacktraces,"CODE_SNIPPETS" : existing_snippets
LLM Prompt:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 <system > </system > <user > <stacktraces > </stacktraces > <code_snippets > </code_snippets > </user >
阶段 5: 上下文过滤 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def _filter_code_snippets (self, requests, code_snippets, config ):"""使用 LLM 过滤代码片段""" for snippet in code_snippets:self .filter_code_snippets_chain.invoke({"REQUESTS" : "\n" .join(req.request for req in requests),"CODE_SNIPPET" : snippetif is_relevant:return filtered
过滤 Prompt:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <system > </system > <user > <requests > </requests > <code_snippet > </code_snippet > <is_relevant > TRUE/FALSE</is_relevant > </user >
阶段 6: 上下文压缩 目标:从 50,000 行代码压缩到 8,000 tokens 的相关片段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def compress_context (self, code_snippets ):"""压缩上下文""" sum (snippet.token_count for snippet in code_snippets)if total_tokens <= MAX_CONTEXT_TOKENS:return code_snippetsself .llm.evaluate_importance(code_snippets)for snippet in important_snippets:return compressed
压缩规则:
保留漏洞所在函数
保留直接调用/被调用的函数
移除无关的注释
只保留关键变量定义
示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 "heap-buffer-overflow" ,"png_read_row\npng_read_image" ,"..." while not satisfied:"I need to find png_read_row function where the overflow occurs" "png_read_row" , "src/png.c" )"Found function. I can see memcpy on line 1234. Need to check buffer allocation." "PNG_BUFFER_SIZE" , "src/" )"Found buffer size constant. Need to check if there's any bounds checking." "png_read_row" )"Now I have enough context: png_read_row, its callers, and buffer size. I can track this snippet." "src/png.c" ,"png_read_row" ,"Vulnerable function with missing bounds check" print (snippets)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 ["src/png.c" ,100 ,105 ,"#define PNG_BUFFER_SIZE 1024" ,"Buffer size constant definition" "src/png.c" ,1228 ,1240 ,""" void png_read_row(...) { row_buf = malloc(row_buf_size); // Line 1230 // NO BOUNDS CHECK HERE! memcpy(row_buf, input_data, size); // Line 1234 } """ ,"Vulnerable function: missing bounds check before memcpy" "src/png.c" ,1100 ,1110 ,""" void png_read_image(...) { ... png_read_row(...); // Calls vulnerable function ... } """ ,"Caller of vulnerable function"
3.多智能体补丁生成 智能体架构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 # buttercup/patcher/src/buttercup/patcher/agents/leader.py
智能体 1:Root Cause Agent(根因分析专家) 职责 :分析漏洞的根本原因
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # buttercup/patcher/src/buttercup/patcher/agents/rootcause.py
输出示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <root_cause_analysis>
智能体 2:SWE Agent(软件工程师) 职责 :设计补丁策略并生成补丁代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 # buttercup/patcher/src/buttercup/patcher/agents/swe.py
输出示例:
1 2 3 4 5 6 7 8 9 10 11 --- a/src/png.c
智能体 3:QE Agent(质量工程师) 职责 :测试补丁的正确性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 # buttercup/patcher/src/buttercup/patcher/agents/qe.py
测试流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1. 应用补丁
智能体 4:Reflection Agent(反思专家) 职责 :当补丁失败时,分析原因并改进
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # buttercup/patcher/src/buttercup/patcher/agents/reflection.py
完整工作流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 ConfirmedVulnerability 到达